
The Zoomdata JavaScript SDK is a library which helps to query data from Zoomdata’s server for different data sources. The SDK allows developers to connect to Zoomdata server, handle web socket connections, in/out messages in it and so on. Third-party developers can start developing their own apps using the SDK. You have to initialize the Client instance, then run some queries based on the data source. Precise steps of how to initialize and make queries are described here: https://www.zoomdata.com/docs/2.6/using-a-data-query.html or at the npm package page: https://www.npmjs.com/package/zoomdata-client
More information is available here: https://www.zoomdata.com/docs/2.6/getting-started-with-the-sdk.html
How MetaData helps creating valid Queries for Zoomdata server
One of the issues faced by developers when creating applications using the Zoomdata SDK is to get list of correct values for Aggregation/Metrics collections. Aggregations are used to group data on server side, while Metrics represent the numeric values calculated based on aggregated data.
For example, you want to build visualization that show the sum of Planned Sales column for different states:

In the example, above we asked Zoomdata to aggregate data by ‘userstate’ column and calculate sum of ‘Planned Sales’ column for each result for ‘userstate’.
But how can the developer know that ‘userstate’ is suitable for Aggregation collection and Planned Sales can be used for Metrics?
In releases prior to Zoomdata 2.6, finding the correct ‘userstate’ was difficult. A developer would have to make an additional REST call to http://localhost:8080/zoomdata/service/sources/599aca5b3004ec987a01a333, where last part of URL is a source’s unique identifier in Zoomdata. Then parse the response, read ‘objectFields’ collection, read ‘formulas’ collection, merge them. After this, the developer has trouble understanding which fields are valid to be sent in aggregation collection, and which ones are good for metrics collection:
For example, the ‘metrics’ collection, only fields of numeric types are suitable. Each metric field could have different metric functions: Average, Min, Max, Sum, Last Value, Distinct Count. You never know valid list of functions for specific source. For Impala, Zoomdata can use ‘last value’ metric function. But this is not available for CSV/JSON/XML sources.
In versions before Zoomdata 2.6, we had logic written at Front End side which knew how to deal with all of these different fields. But this logic was not accessible for third-party developers and was tricky to implement internally at Zoomdata. With the release of version 2.6, these issues have been resolved.
In Zoomdata 2.6, we introduce a new endpoint in the SDK API: createMetaThread. MetaThread is a bi-directional way to ask for information regarding metadata from server. You can issue commands to MetaThread instance and listen to responses.
This call is used to initiate the opening of a web socket. This web socket connection is used by SDK to query server for a list of valid aggregations, metrics, filters for specific source.
Let’s write these functions which initialize SDK instance, connects to the server, and queries for all metadata info for source:
async function initMetaThread() {
const client = await ZoomdataSDK.createClient({
credentials: {
key: '<your_key>',
},
application: {
secure: false,
host: 'localhost',
port: 8080,
path: '/zoomdata',
},
});
const metaThread = await client.createMetaThread({});
const metaData = await metaThread.requestMetaDataForSourceId(
'599acb153004ec987a01a403',
);
return metaData;
}Here on line #2, we call ZoomdataSDK’s createClient method. This method is used to initiate connection to server and validate you provided correct credentials.
**On line #4, **you have to provide Zoomdata’s key to be able to access our API. Refer to https://www.zoomdata.com/docs/2.6/generating-a-security-key.html for more info.
Lines #6–10 are straightforward: you have to provide the correct connection details. If you are developing on local machine then leave it as provided, if not — then modify according to your setup.
Line #13 is where we actually create **MetaThread **instance. For this article, we provide the empty object as input. Next, we go over how you can get very specific combinations of aggregations/metrics used in Zoomdata to create complex valid queries. After executing this line, you can see new web socket connection opened in Chrome Dev Tools. Currently, the connection has no output/input messages.
Line #14 is where we issue command to MetaThread instance to get some MetaDataResponse for us. Be sure to provide your own source id. They are unique for each Zoomdata server instance. You can get source id value by doing GET REST call to http://localhost:8080/zoomdata/service/sources. Just find needed source and copy its ‘sourceId’ value.
After this line is executed, you will see the following in the in web socket:

The message in green is an outgoing message to the server. MetaThread automatically generated full MetaDataRequest messages based only on the source id provided in requestMetaDataForSourceId call.
metaThread.requestMetaDataForSourceId resolves promise with the instance of MetaDataResponse class. This instance has a special API to help you get the data you need.
Now let’s add the function which calls our async initMetaThread function:
const initApp = async () => {
const meta = await initMetaThread();
console.log('Received meta data for source: ', meta);
};Save JavaScript code as app.js.
Create index.html to run this JavaScript:
<html>
<head>
<title>Zoomdata Meta Service</title>
<script src="http://developer.zoomdata.com/zoomdata-2.6/sdk/zoomdata-client.js"></script>
<script src="./app.js"></script>
</head>
<body>
</body>
</html>Pay attention to line #5: it must point to the correct bundle of Zoomdata SDK. You can refer to our docs: https://www.zoomdata.com/docs/2.6/getting-started-with-the-sdk.html. Or you can install Zoomdata SDK from npm: https://www.npmjs.com/package/zoomdata-client.
Use any static server and open a localhost in a browser window. I use https://www.npmjs.com/package/serve:
$ serve ./ -p 3001This runs static HTTP server.
Now open Chrome and go to http://localhost:3001
You should see a similar message in the console:

This means our JavaScript code initialized the SDK, opened a web socket connection, and asked MetaThread about metadata for specific source.
Now stop the debugger on line #20 and refresh the page. Then call:
metaData.getAllAggregations();A similar list will be printed in your console:

There are just three types of Aggregations in Zoomdata — Time, Terms and Histogram. They are all very specific but share some common methods.
For example, you can get list of all names suitable for Aggregation collection:
metaData.getAllAggregations().map(aggregation => aggregation.getName());Here we get all instances of aggregations, then map to get only their names:
[
"_ts",
"category",
"county",
"countycode",
"group",
"plannedsales",
"price",
"record_hour",
"sku",
"usercity",
"usergender",
"userincome",
"usersentiment",
"userstate",
"zipcode"
]Or you can get user-defined labels:
metaData.getAllAggregations().map(aggregation => aggregation.getLabel());This will print:
[
"Ts",
"Category",
"County",
"Countycode",
"Group",
"Plannedsales",
"Price",
"Record Hour",
"Sku",
"Usercity",
"Usergender",
"Userincome",
"Usersentiment",
"Userstate",
"Zipcode"
]What about metrics?
metaData.getAllMetrics();This will print a list of instances with different Metrics available for you.

All of the instances have API to get metric names, labels:
metaData.getAllMetrics()[0].getLabel();
//"Countycode"Let’s return to our task: getting all suitable aggregations for our query.
If we want to build a visualization of the Bars type (actually any visualization but not Histogram visualization), we have to provide only the attribute fields in aggregation collection. Using the new SDK, we can call another method:
metaData.getAttrAggregations();Attribute aggregation is a set of Time and Terms aggregations.
This method will print only attribute aggregations:

Compare this to
metaData.getAllAggregations();which outputs 15 instances but now we have only 11. So 4 of them are not suitable to be set for attribute aggregation! (They are actually aggregations used for Histogram type visualizations).
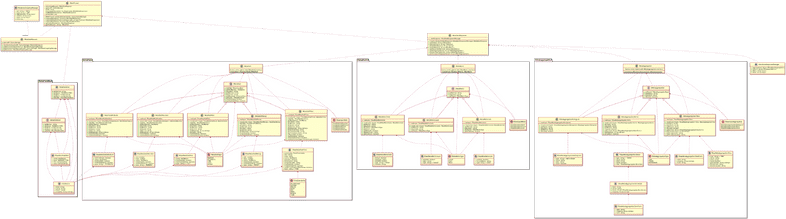
You can refer to this UML
diagram
to get list of all available methods and how their instances connect to each
others:
Zoomdata SDK provides some TypeScript typings in SDK package from npm but not everything is exposed (yet). So if you use TypeScript in your application, then you can just:
import { IMetaAggregation } from 'zoomdata-client';And the interface for IMetaAggregation is available for you.
Link to github repository with code: https://github.com/gladimdim/posts-zoomdata-sdk/tree/master/post_1


